
It’s impossible to write OOP code with Spring. From its core it promotes the use of singletons and anemic data structures a.k.a. data “objects” a.k.a. DTO. This fuels procedural programming and kills OOP.
In the next paragraphs I’ll highlight three major Spring components involved. I start from the core.
IoC Container
The core of Spring is the IoC container, represented by the ApplicationContext interface.
Basically it defines a context through which we get beans. A bean is an object managed by the container and it has a name attached to it.
We can configure the context thanks to some annotations, called steorotype. These annotations were introduced in Spring 2.5 and enhanced in Spring 3.0. Previously we could only use an external XML. This was even worse…
So we annotate a class with a stereotype, the container reads it and it builds a bean. A bean is a singleton. For this reason it cannot represent anything specific. This means that to do something useful we should pass around data “objects” through them.
A bean is an object only from a technological point of view. But at the conceptual level it’s just a namespace for procedures. In other words it’s a bunch of procedure grouped by a name. Nothing more. Every bean, regardless the stereotype, is bad.
This is not OOP. But I’m not saying anything new. It’s known that singleton are bad. But this (anti)pattern is the Spring backbone.
At this point it should suffice to say that everything else in Spring is based on bean. This means that every Spring application is composed by bean that works on data structure. Definitely this is not OOP.
However I think that things gets worse with the next two components…
Spring MVC
The MVC architecture is one of the most used and it’s based on three components:
- Model, it manages the state;
- View, it’s a representation (e.g. HTML or JSON) of the model;
- Controller, it handles user (not necessarly a person) input.
Here is a sketch from the Martin Fowler blog:
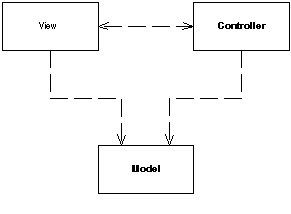
So an user interacts with the controller. Then the latter communicates with the model and finally it returns a view to the user. The view knows how to represent the model.
But, in order to represent it, the view should break encapsulation. Indeed it should have direct access to the model attributes. And there isn’t any difference if the model exposes getters.
The issue is that the model is not respected. It’s treated as a bag of data. But in OOP way of thinking only the model should know its internal and only the model should know how to represent itself. Nobody else should know either. Currently I’m using the Printer pattern to support multiple representations (e.g. JSON or XML).
This issue is not Spring specific, but it’s related to the MVC architecture.
However this is an example of a Spring RestController that exposes the dangers:
@RestController
@RequestMapping("/books")
public class BooksController {
@GetMapping
Collection<Book> getBooks() {
// ....
return theBooks;
}
}
The method getBooks returns a collection of books. Spring MVC converts each Book to JSON.
But in order to do this it requires to break encapsulation (with getters or JSON serializer or other mechanism).
In other words the Book should be a data structures. Or it should be a mix between an object and a data structure. A terrible design, a monster.
Spring Data
When I started to learn Spring Data I was really impressed about its power… Now I’m worried about its role because it’s very dangerous to OOP.
There is a central component in the Spring Data project: the Repository interface.
It abstracts the access to a database and manages the lifecycle of an entity. Every entity has an ID associated.
Every method of a repository represents a query to the underlying database. We can define the queries manually. However Spring Data can derive them from method names according some keywords. It’s powerful.
For example, assuming SQL, from a method called findAll it derives SELECT * FROM TABLE_NAME.
To get a repository all we need is to write a Java interface that respects some rules. Then Spring builds a bean and we gat it from the context.
The rules are pretty simple. The interface should extends Repository. While the methods should respect the aforesaid keywords.
This is an example of a repository:
interface BookRepository extends Repository<Book, Long> {
Collection<Book> findAll();
Optional<Book> findById(Long id);
}
Book refers to the managed entity, Long to the type of its id. And it supports two method:
findAll, through which we can get all the books in the database;findById, through which we can get the book associated with an id.
As I said every query is generated by Spring Data. We don’t need anything else. Spring does all the job.
Then this is an example of the Book entity:
@Entity
@Table(name = "BOOK")
class Book {
@Id
private Long id;
private String title;
private Double price;
// no args constructor, getters and setters omitted
}
Spring Data requires:
- an attribute annotated with @Id;
- a no argument constructor;
- a setter for each attribute.
As easily imaginable Spring Data requires an anemic data structure.
Conclusion
Clearly Spring promotes anemic “objects”. For this reason is normal to find in Spring application bunch of procedures collected in bean. Where each procedure manipulates some data structures.
I loved Spring. But I’m not using it anymore for the benefit of maintainability and simplicity. And OOP is better than procedural programming because it improves them.